Variational Method#
Recall that in quantum mechanics, the ground state can be defined variationally as
To obtain exact result, the minumum is taken over full Hilbert space, but we can obtain upper bound on ED by a fewparameter anstatz \(\quad\left|g_{1,}, g_{2}, \cdots\right\rangle,\left(e_{\text {.g. }, ~}|g\rangle=e^{-\frac{1}{2} g r^{2}}\right)\)
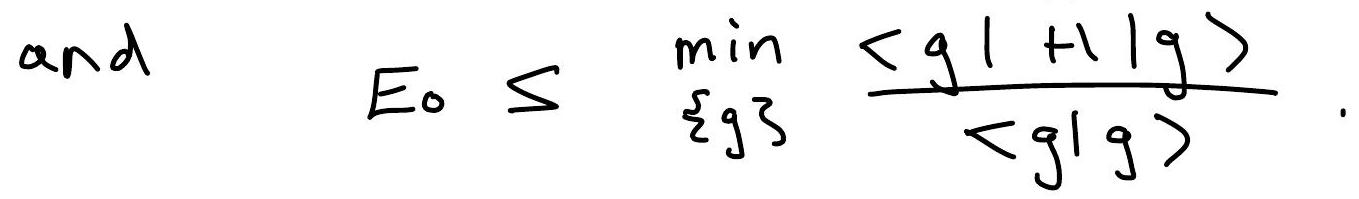
The \(|g\rangle\) obtained in this way is in this sense the “best” approximation to \(\left|E_{0}\right\rangle\) in the Hilbert subspace \(\mid \{ g\} \rangle\).
We can do something similar in statistical physics.
Given \(T, H\), we define the free-energy of an arbitrary distribution \(\rho\) by
where we’ve used the Gibbs entropy
Recall that \(\rho_{\beta}=\frac{1}{Z_{\beta}} e^{-\beta H}=e^{-\beta (H-F_0)}\) minimizes \(F\) :
(Because \(\rho_\beta\) maximizes the Gibbs entropy subject to \(\langle E\rangle\))
Given a few-parameter ansatz \(\rho_{\mu}(g)\), we can then define our best approximation as
and use \(\rho(g)\) to compute approximate observables.
Note that there is a simple way to see that ()is true. Using \(\rho_{\beta}=e^{-\beta (H-F_0)}\), we can write
showing that the difference between the approximate and true free energy is proportional to the “KL” divergence
which is non-negative (see Shannon entropy lecture, eq. (2)).
It is convenient to parameterize \(\rho(g)\) as a Boltzmann distribution corresponding to a fictitious Hamiltonian \(H_g\),
Consider, for example, the generalized Ising Hamiltonian
where the notation \(\langle i, j\rangle\) indicates that sites \(i\) and \(j\) are in contact (i.e. they are nearest neighbors) and each pair is only counted once. We might then choose \(H_{g}=-g \sum_{i} \sigma_{i}\), where \(g\) is a parameter we will adjust. In terms of \(H_g\), we have
Defining \(\quad e^{-\beta F_{g}}=Z_{g}= \sum_{\mu} e^{-\beta H_{g}(\mu)}\quad\left(F_{g} \neq F[p(g)) !\right)\), we have
The lower bound
is called the “Gibbs’s inequality”. It can be rewritten as
Let’s try this for
We need to compute \(Z_{g},\left\langle H_{g}\right\rangle_{g},\langle H\rangle_{g}\)
which depends on the mean magnetization \(m_g\) under the fictitious Hamiltonian,
And crucially, because under \(\rho_{g}\) the different spins are uncorrelated,
we obtain for the \(\rho_g\) averaged energy
where \(\zeta\) is the number of nearest neighbors each spin has - the so-called coordination number.
Putting it all together
Now, finally, we minimize (\(m_{g}^{\prime}=\partial_{g} m_{g}\)):
This has a simple physical interpretation: in \(H=-J\sum_{\langle i, j\rangle} \sigma_{i} \sigma_{j}\), each \(\sigma_{i}\) sees “on average” a field \(J \zeta \langle \sigma_i\rangle_g=J \zeta m_g\) induced by its neighors - suggesting \(H\approx -J \zeta m_g\sum_i \sigma_i\). Since \(H_{g}=-g \sum_i \sigma_{i}\), the condition is \(g=J \zeta m_g\).
We can solve \(g=J \zeta \tanh (\beta g)\) analytically for small \(g\) :
Solution \(1: g=0 . \longrightarrow m_{g}=0\)
But for \(T \zeta \beta>1\),
Solution 2: \(\beta g= \pm \sqrt{3\left(1-\frac{1}{J \zeta \beta}\right)}\)
For \(J \zeta \beta>1\), it can be verified this is lower-F solution: symmetry breaking!
Graphical Solution
Is this variational approximatition good? It knows about the lattice and dimensions \(D=1,2,3\) only through coordination number \(\zeta\). e.g., for square lattice \(\quad z=2 D \)
But we know that the exact solution of 1D Ising model does not have symmetry breaking: the variational result is bad in 1D. On the other hand, if \((D, z) \rightarrow \infty\), you can verify \(F[\rho(g)]\) is identical to the exact result of the all-to-all model: it is good in large \(D\) and large \(\zeta\).
For \(D=2,3\), the accuracy is intermediate; it correctly predicts symmetry breaking but doesn’t get \(T_{c}\) or \(m \sim\left|T-T_{c}\right|^{\beta}\) quantitatively right.